

CAR
In machine learning, a question of great interest is understanding what examples are challenging for a model to classify. Identifying challenging examples helps inform safe deployment of models, isolates examples that require further human inspection, and provides interpretability into model behavior. We start with a simple hypothesis – examples that a model has difficulty learning will exhibit higher variance in gradient updates over the course of training. On the other hand, we expect the backpropagated gradients of the samples that are relatively easier to learn will have lower variance.
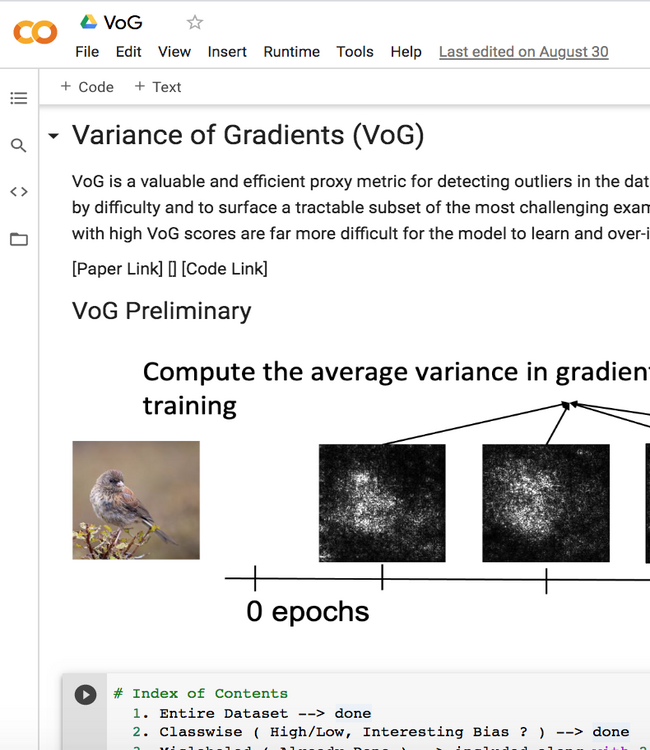
In this work, we propose Variance of Gradients (VOG) as a valuable and efficient proxy metric for detecting outliers in the data distribution. We provide quantitative and qualitative support that VOG is a meaningful way to rank data by difficulty and to surface a tractable subset of the most challenging examples for human-in-the-loop auditing. Data points with high VOG scores are far more difficult for the model to learn and over-index on corrupted or memorized examples


VOG offers an efficient method to rank the global difficulty of examples and automatically surface a possible subset to aid human interpretability. VOG can be computed using checkpoints stored over the course of training and is model agnostic. Alternatively, VOG can be computed using the predicted label, which makes it an unsupervised auditing tool at test time.
The primary contributions of our work can be summarized as follows:
VoG can be an effective tool to audit high-dimensional datasets. Below, we plot images from late-stage training for randomly selected classes from CIFAR-10 and CIFAR-100. We observe consistent results in differences between Low VoG and High VoG samples across both datasets.
Low VoG exemplars: Images that are assigned low VoG scores tend to have clear, distinct images of the class in question. We also observe different color bias patterns emerge during early training for certain classes.
High VoG exemplars: Images that are assigned high VoG scores usually contain unusual vantage points and/or have obstructed views of the class.
CAR

FROG

BIRD

CAR

FROG

BIRD

PLANE

TRUCK

HORSE

PLANE

TRUCK

HORSE

BED

BICYCLE

LEOPARD

BED

BICYCLE

LEOPARD

SPIDER

SUNFLOWER

TURTLE

SPIDER

SUNFLOWER

TURTLE
Pre-computed VoG scores for MNIST/CIFAR-10/CIFAR-100 are available here.
We welcome additional discussion and code contributions on the topic of this work. A comprehensive introduction of the methodology, experiment framework and results can be found in our paper and open source code.
If you use this software, please consider citing:
@inproceedings{agarwal2022estimating,
title={Estimating example difficulty using variance of gradients},
author={Agarwal, Chirag and D'souza, Daniel and Hooker, Sara},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10368--10378},
year={2022}
}